ДНК-компьютер: код жизни на службе технологий. Как...
ДНК-компьютер: код жизни на службе технологий. Как молекулы решают проблемы хранения данных и сложных вычислений
04 марта 2025, 19:10
Статья на конкурс "Био/Мол/Текст": В данной статье автор рассмотрел ДНК-компьютер как альтернативу современным компьютерам в решении задач хранения данных и сложным вычислений, принципы практической реализации, преимущества и недостатки этой технологии, а также перспективы ее дальнейшего развития. Представьте мир будущего. Вся библиотека данных человечества помещается в крошечном контейнере. За считанные секунды люди моделируют сложнейшие биологические процессы и прогнозируют климатические изменения. Из этой статьи вы узнаете, как ДНК-компьютер может стать альтернативой традиционным компьютерам для хранения данных и выполнения сложных вычислений. Мы рассмотрим основы работы этой технологии, ее практическую реализацию, основные преимущества и ограничения, а также оценим перспективы ее дальнейшего развития и потенциального применения в будущем.
Эта работа опубликована в номинации "Школьная" конкурса "Био/Мол/Текст"-2024/2025. Генеральный партнер конкурса — международная инновационная биотехнологическая компания BIOCAD. "Книжный" спонсор конкурса — "Альпина нон-фикшн" Мы привыкли думать, что информация хранится исключительно на электронных носителях: жестких дисках, флешках или облачных серверах. Проблема в том, что количество данных постоянно растет, и с развитием человечества их будет становиться только больше, а перенос данных со старых носителей на новые уже сейчас существенно добавляет к расходам на хранение данных. Современные, привычные нам кремниевые компьютеры уже не являются новейшей технологией, и их возможности имеют некоторые пределы, обусловленные их структурой и свойствами материалов, из которых они созданы. Перед человечеством появляются новые задачи, для решения которых имеющегося потенциала кремниевых компьютеров не хватает. Какие альтернативы может предложить современная наука? Наверняка вы слышали про квантовые компьютеры, но сегодня речь пойдет не о них, а о другом виде вычислительных устройств, относящемся к категории нетрадиционных вычислений ( Unconventional Computers) — ДНК-компьютере.
ДНК-компьютер. А что, так можно было?
Может появиться мысль: а как вообще может существовать компьютер из молекул? Это кажется контринтуитивным: компьютеры ассоциируются с "железом", электричеством. Квантовый компьютер еще кажется более-менее похожим на привычный, но ДНК?... Ответ на этот вопрос неизбежно заставляет нас вспомнить, с чего все начиналось. Почему вообще компьютеры такие, какие они есть сейчас? Людям была нужна автономная система, реализующая какие-то функции, например, счет. Эту задачу можно реализовать многими способами — даже шариками, катящимися по картонным желобкам. Во времена возникновения первых компьютеров у людей "под рукой" был телеграф и магнитные катушки-реле, на основе которых, собственно, и собрали первые вычислительные машины. Получается, то, что наши компьютеры выглядят именно так — просто случайность, обусловленная технологическим развитием человечества того времени! Сначала громко щелкающие магнитные реле были основой компьютеров, затем их сменили более компактные транзисторы, но принципы работы остались такими же. Однако технологии не стоят на месте, и теперь ученые предлагают новую, революционную основу для компьютерной архитектуры — использовать молекулы ДНК для хранения данных и выполнения сложных алгоритмов. Этот метод обещает не только решить проблему растущих объемов информации, но и сделать это эффективнее любых современных технологий.
С чего все начиналось? Леонард Адлеман и задача коммивояжера
Первопроходцем в использовании молекул ДНК для вычислений является один из создателей Интернета — Леонард Адлеман. Именно он в 1994 году создал первый в мире ДНК-компьютер и вдохновил других ученых на развитие этого научного направления. Адлеман предположил, что то, что мы требуем от компьютера, можно получить при помощи создания систем из молекул ДНК, взаимодействующих в растворе [1]. Для тестирования нового подхода Адлеман выбрал классическую задачу коммивояжера (как соединить семь точек так, чтобы через каждую точку пройти только один раз) и реализовал ее решение с помощью разных одноцепочечных последовательностей ДНК, каждая из которых обозначала точку из условий задачи или переход между ними, причем цепочки были специально подобраны так, чтобы концы одной молекулы могли соединяться с концами других молекул из набора. Затем Адлеман размножил эти последовательности и добавил их в раствор, где они сразу же соединились в разных сочетаниях, часть из которых являлись верными решениями задачи. Адлеман в несколько этапов отделял корректные последовательности от остальных при помощи гель-электрофореза и магнитных частиц [1]. В итоге в растворе остались только молекулы, представлявшие собой верное решение. Рисунок 1. Решение задачи коммивояжера. (а): граф, описывающий маршруты между городами; (б): 2 и 3 — последовательности представляющие города, 2–3 — последовательность представляет маршрут между городами; (в): пример соединения городов и маршрутов. Chemistry World Ну и что, спросите вы, что такого удивительного в этом решении задачи на соединение семи точек? Оказывается, данная задача коммивояжера принадлежит особому классу задач — NP-полные задачи, и в области информатики они имеют особое значение.
NP-полные задачи: от судоку до аэропортов
Вы сами сталкивались с NP-полной задачей при решении судоку. Как ни удивительно, оптимизация транспортных маршрутов, логистика магазинов и складов, анализ шифров и хэш-функций, алгоритмы в социальных сетях и многие другие практические задачи относятся к этому же типу задач. Особенность NP-полных задач — в том, что для их решения не существует эффективного алгоритма, и нужно перебрать все возможные варианты. При больших объемах данных эта задача становится почти невыполнимой, так как для традиционных компьютеров процесс вычислений и перебора может занять годы. NP-полные задачи являются серьезной проблемой для всех, кто сталкивается с необходимостью быстро находить решения сложных проблем в условиях ограниченных вычислительных ресурсов, например, для программистов, ученых, бизнес-аналитиков и даже гейм-дизайнеров. И здесь мы снова возвращаемся к эксперименту Адлемана, который доказал потенциал ДНК-компьютеров к практической реализации: в теории они способны производить параллельные вычисления и обрабатывать миллиарды вариантов одновременно, а значит, решать NP-полные задачи значительно быстрее, чем обычные компьютеры. Какие еще возможности, помимо решения сложных задач, дают ДНК-компьютеры? Чтобы ответить на этот вопрос, рассмотрим подробнее, как устроена эта многообещающая технология.
Как устроен ДНК-компьютер?
Современный ДНК-компьютер — это система, построенная на свойствах молекулы ДНК. Он выглядит как целая лаборатория с пробирками, секвенаторами и другими приборами, но это лишь инфраструктура для "компьютера в пробирке", ведь самое интересное происходит в области, невидимой невооруженным глазом — на уровне молекул ДНК и их фрагментов. Комплементарные взаимодействия ДНК в растворе можно достоверно предсказать при помощи термодинамических моделей, зная температуру, кислотность и ионную силу раствора. Таким образом, ДНК, благодаря своей предсказуемости, стала подходящим вариантом основы для альтернативных компьютерных систем. В настоящее время в развитии технологий ДНК-компьютеров существуют две параллельные области: ДНК-вычисления и хранение данных. Рассмотрим каждое из этих этих направлений подробнее.
Замещение цепочек ДНК как один из самых распространенных методов в области ДНК-вычислений
Суть метода замещения цепочек ДНК ( DNA strand displacement, DSD) состоит в том, что одноцепочечная молекула ДНК (входной сигнал) сначала связывается с частично двухцепочечным комплексом, который уже был в растворе, через одноцепочечный домен, называемый "заякоривающим доменом" ( toehold, на рисунке 2 а он и часть входного сигнала, которая связывается с ним, обозначена красным), а затем благодаря большей комплементарности постепенно разрывает связи выходного сигнала с цепочкой, на которой он держался ("ворота"), и связывается с воротной цепочкой вместо первоначально связанной цепи (выходной сигнал) — см. рис. 2 б [2]. Молекула ДНК может служить сигналом, когда она находится в свободном состоянии, но подавляется, если связана с комплементарной цепью. Таким образом, выходной сигнал может быть активирован при поступлении входного сигнала. Выпущенная одноцепочечная молекула может вытеснять уже другую, повторяя процесс и потенциально создавая длинную цепочку сигналов. Этот механизм является основным строительным элементом ДНК-компьютеров, как реле являлись строительным элементом классических компьютеров. Его можно усложнять и развивать, комбинировать между собой разные механизмы для создания очень сложных систем. Рисунок 2. Замещение цепочек ДНК. (a) — в ДНК-компьютерах используется способность ДНК связываться комплементарно; (б) — на основе вытеснения одних олигонуклеотидов другими можно создать логические вентили и нейросети. Систему можно усложнить при помощи компартментализации (дополнительных наноструктур в пробирке); (в) — "центральная догма" записи информации в ДНК. [2] Ниже представлен механизм ДНК-вычисления на основе наночастиц и компартментализации. Рисунок 3. ДНК-вычисления на основе наночастиц и компартментализации.(а) — модифицированные ДНК-наночастицы на липидном бислое используются в качестве вычислительной памяти (M), подвижных элементов (F) и репортерных единиц (R). Наночастицы памяти и репортеров неподвижны, тогда как подвижные элементы могут диффундировать и сталкиваться с другими наночастицами. Добавление ДНК-входов изменяет состояния гибридизации в памяти, информация из которых обрабатывается подвижными элементами и затем передается репортеру. Двоичный выход (1 или 0) определяется связыванием или отсутствием связывания между подвижным элементом и репортером, которое различается по цвету рассеяния наночастиц. Комбинация множества наборов памяти, подвижных элементов и репортеров позволяет программировать нейронные сети, подобные перцептрону [2]. (б) — благодаря разделению на капли "вода в масле" ферментативная ДНК-цепь может количественно усиливать и передавать наличие микроРНК; (в) — везикулы, содержащие ДНК-реакционные сети, могут использоваться для восприятия, анализа и обработки непрерывных колебаний внеклеточных стимулов. Ключевым модулем является фильтр колебаний, состоящий из контуров прямой передачи и пороговых элементов; (г) — ДНК-цепи, заключенные в протеиносомы через взаимодействие стрептавидина и биотина, могут воспринимать, обрабатывать и секретировать короткий одноцепочечный выходной ДНК через механизм смещения ДНК-цепи. Отдельные протеиносомы можно настроить для выполнения различных распределенных вычислительных задач, включая обнаружение, преобразование сигналов, каскадирование, усиление, логику и обратную связь; (д) — ДНК-дроплеты могут функционировать как безмембранные компартменты для управления молекулярными вычислениями. Y-образные ДНК-структуры (фиолетовые круги) с самокомплементарными липкими концами (непарные нуклеотиды, которые могут связывать сегменты ДНК) конденсируются в динамические капли, способные вмещать ДНК-клиенты (красные круги) для различных вычислений; (е) — микрофлюидный чип на основе полидиметилсилоксана (PDMS) предоставляет автоматизированное управление и программируемое выполнение логических операций Булевой алгебры. [2]
Система хранения данных на базе ДНК
Ни для кого не секрет, что ДНК состоит из четырех основных азотистых оснований: аденина, цитозина, гуанина и тимина, обозначаемых буквами A, C, G и T, соответственно. Каждому их них можно присвоить двоичное значение. Получается, что биты информации можно кодировать при помощи нуклеотидов ДНК, и наоборот [3]. Рисунок 4. Система хранения данных на базе ДНК. [3] Для хранения информации в ДНК двоичный код по определенным правилам переводят в последовательность нуклеотидов. Затем создают молекулу ДНК с такой последовательностью и отправляют ее на хранение. Когда информацию нужно прочитать, ее извлекают из хранилища, секвенируют, и переводят в двоичный код. Конечно, ДНК-хранилище данных не является просто пробиркой с плавающими там последовательностями. Учеными были придуманы специальные системы хранения ДНК-данных для увеличения надежности хранения и простоты прочтения. Также, было бы неудобно, если бы для того, чтобы отредактировать данные, их нужно было вылавливать и заново синтезировать. Для этого было предложено использовать CRISPR, ферменты или уже знакомое нам замещение цепи. Рисунок 5. (а), (б) — положенные на хранение ДНК физически отделяют друг от друга, помещая в разные ячейки, чтобы они не перепутались. В (а) молекулы ДНК хранятся вне воды, в разных ячейках специальной структуры. В (б) молекулы ДНК помещаются в разные структуры внутри раствора. (в) — на структуры-хранилища ДНК вешаются флуоресцентные метки для облегчения сортировки. (г) — на ДНК вешаются магнитные частицы. (д), (е) — после того, как ДНК-хранилище данных было синтезировано, его можно редактировать при помощи CRISPR—Cas. (ж) — редактирование сохраненных данных при помощи замещения цепи ( strand displacement, DSD). [3]
Прорыв в области хранения ДНК. Успешный опыт кодирования и считывания данных с помощью ДНК-компьютера
Метод DNA Fountain, описанный в 2017 году в журнале Science, — прекрасный пример перспективной технологии хранения и обработки информации на базе ДНК-компьютера [6]. Ученые успешно закодировали 2 мегабайта данных, включая фильм и операционную систему, и показали, что их метод может позволить закодировать до 215 (!) петабайт данных в одном грамме ДНК. Для сравнения: в одном петабайте можно записать все игры с сервиса Steam. Таким образом, оптимизация технологии хранения информации в ДНК позволила приблизиться к теоретическому пределу плотности хранения информации, описанному Клодом Шенноном, на 85% [4]. До этой работы ученым сильно мешало то, что во время репликации ДНК достаточно часто случаются ошибки. Когда репликация происходит внутри клетки, то работают внутриклеточные механизмы по исправлению этих ошибок, а в случае с культивированием ДНК вне клетки таких механизмов нет. Одноцепочечные молекулы ДНК отличаются между собой сильнее, чем транзисторы в компьютере, поэтому в кремниевых компьютерах ошибки распределены равномерно, а в ДНК — нет. Это еще больше осложняет попытки сделать точные запись и считывание данных. В методе DNA Fountain ученые смогли изобрести и реализовать "хитрый" алгоритм перевода двоичного кода в ДНК, который позволил свести количество ошибок к нулю: им удалось успешно записать и прочитать данные с ДНК без единой ошибки и без потерь данных, с идеальной точностью.
Преимущества ДНК-компьютера: забота о планете, снижение расходов и долговечность
Среди важных преимуществ технологии стоит выделить ее энергоэффективность и экологичность. Хранение ДНК обладает минимальным энергопотреблением, так как не требует постоянного электричества, как современные серверы привычных нам компьютеров [5]. Использование биокомпьютеров делает вычисления экономически более выгодными [5]. Немаловажно и то, что производство и использование ДНК для хранения данных менее вредно для окружающей среды, так как может снизить углеродный след, который создают традиционные центры обработки данных [5]. Но и это еще не все: ДНК может сохранять информацию тысячелетиями, если ее хранить в правильных условиях [3]. Получается, что ДНК-компьютер — один из самых плотных и долговечных носителей информации.
Оборотная сторона инноваций. Почему ДНК-компьютер нельзя заказать на маркетплейсе и использовать в калькуляторах на контрольных в школе
Почему же человечество еще не перешло на ДКН-компьютеры, если они так хороши? Действительно, до массового производства еще далеко. Любая революционная технология с большим научным потенциалом неизбежно сталкивается с вызовами. Основная проблема ДНК-компьютера — низкая скорость работы. Если бы мы жили в идеальном мире, где реакции молекул происходят с большой скоростью и верный ответ NP-полной задачи можно сразу посчитать, то современные суперкомпьютеры можно было бы смело отправлять на свалку истории. В реальности же чтение и запись данных с ДНК и на ДНК пока происходят несравнимо медленнее современных компьютеров. Еще одна проблема — неполная предсказуемость взаимодействий между молекулами. Эта проблема стоит особенно остро для гипотетических внутриорганизменных биокомпьютерных систем и области синтетической биологии. Подробнее про эту интересную сферу можно прочитать в статье "Биомолекулы": "Синтетическая биология: от программирования компьютеров к программированию клеток" [5]. И наконец, существует весьма прозаическая, хотя и серьезная проблема: высокая стоимость синтеза и секвенирования ДНК. Для массового производства будет необходим простой интерфейс для взаимодействия с ДНК-компьютером, ведь далеко не каждый обладает навыками работы в "мокрой" лаборатории.
Российский вклад в развитие ДНК-компьютера и перспективы технологии
Каждый из описанных выше процессов предстоит усовершенствовать и раскрыть заложенный в них научный потенциал. Примером нестандартного подхода в этой и так нестандартной теме может служить использование низкоафинных взаимодействий, которое предложил российский ученый Максим Никитин [6]. Он создал биокомпьютер, использующий низкоафинные взаимодействия олигонуклеотидов, и этот подход противоположен тому, как обычно подходят к ДНК-вычислениям, используя аффинные взаимодействия. До Никитина эти взаимодействия не принимались во внимание, но оказалось, что они играют важную роль в процессах внутри человеческого организма: например, с ними могут быть связаны побочные эффекты генной терапии и многие другие неожиданные закономерности. На "Биомолекуле" есть пересказ его научной статьи по этой тематике — советую прочитать его, если эта тема вызывает интерес [7]. Несмотря на все описанные в этой статье сложности, ДНК-компьютеры меняют наше представление о том, как решать сложнейшие задачи и хранить данные. Эта технология уже выходит за рамки теории, показывая свою жизнеспособность в реальных проектах таких компаний, как Catalog, Evonetix, Molecular Assemblies и более 20 других. В будущем молекулы ДНК станут основой для вычислительных систем, способных изменить мир. Кто знает, может быть через n-цать лет любители науки будут читать эту статью на ДНК-компьютере и улыбаться дерзости научной мысли, которая, как и многие сотни раз до этого, вышла за рамки привычного.

 Генеральный партнер конкурса — международная инновационная биотехнологическая компания BIOCAD.
Генеральный партнер конкурса — международная инновационная биотехнологическая компания BIOCAD.  "Книжный" спонсор конкурса — "Альпина нон-фикшн" Мы привыкли думать, что информация хранится исключительно на электронных носителях: жестких дисках, флешках или облачных серверах. Проблема в том, что количество данных постоянно растет, и с развитием человечества их будет становиться только больше, а перенос данных со старых носителей на новые уже сейчас существенно добавляет к расходам на хранение данных. Современные, привычные нам кремниевые компьютеры уже не являются новейшей технологией, и их возможности имеют некоторые пределы, обусловленные их структурой и свойствами материалов, из которых они созданы. Перед человечеством появляются новые задачи, для решения которых имеющегося потенциала кремниевых компьютеров не хватает. Какие альтернативы может предложить современная наука? Наверняка вы слышали про квантовые компьютеры, но сегодня речь пойдет не о них, а о другом виде вычислительных устройств, относящемся к категории нетрадиционных вычислений ( Unconventional Computers) — ДНК-компьютере.
"Книжный" спонсор конкурса — "Альпина нон-фикшн" Мы привыкли думать, что информация хранится исключительно на электронных носителях: жестких дисках, флешках или облачных серверах. Проблема в том, что количество данных постоянно растет, и с развитием человечества их будет становиться только больше, а перенос данных со старых носителей на новые уже сейчас существенно добавляет к расходам на хранение данных. Современные, привычные нам кремниевые компьютеры уже не являются новейшей технологией, и их возможности имеют некоторые пределы, обусловленные их структурой и свойствами материалов, из которых они созданы. Перед человечеством появляются новые задачи, для решения которых имеющегося потенциала кремниевых компьютеров не хватает. Какие альтернативы может предложить современная наука? Наверняка вы слышали про квантовые компьютеры, но сегодня речь пойдет не о них, а о другом виде вычислительных устройств, относящемся к категории нетрадиционных вычислений ( Unconventional Computers) — ДНК-компьютере. 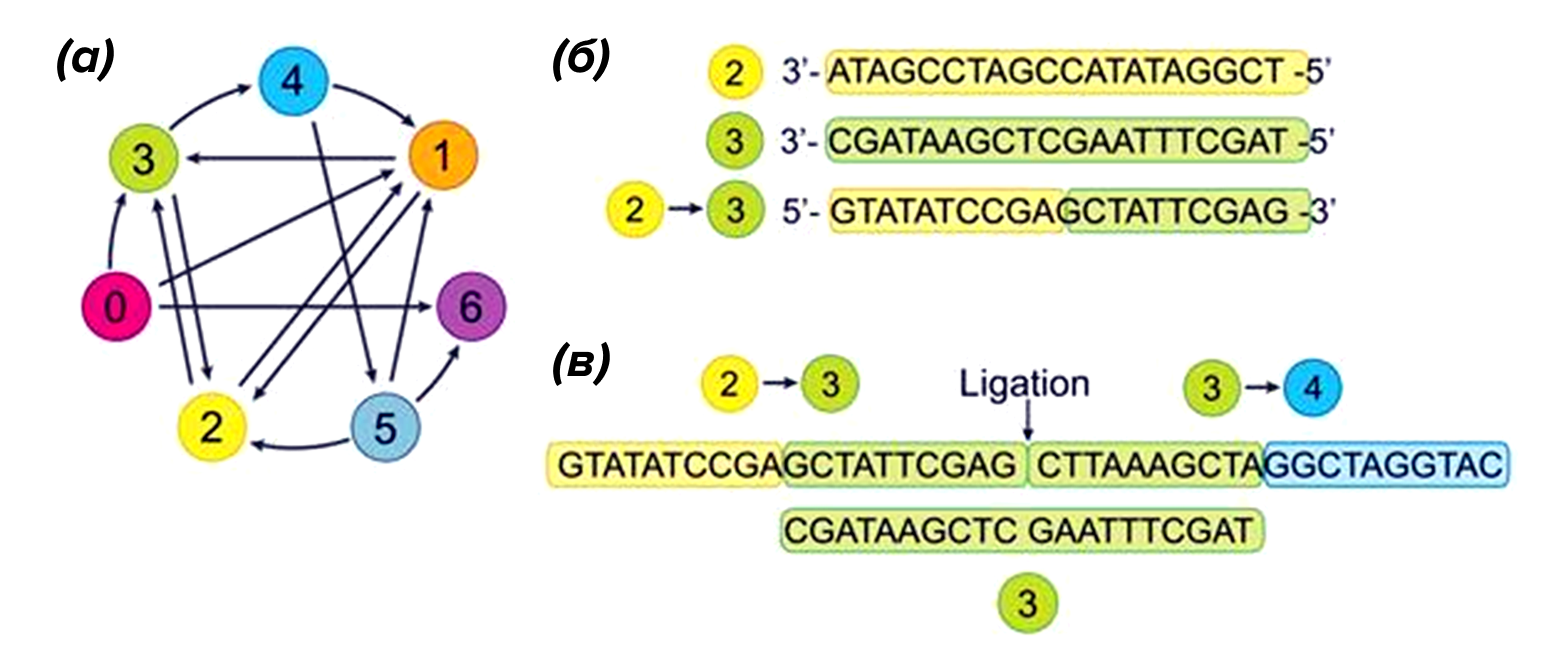 Рисунок 1. Решение задачи коммивояжера. (а): граф, описывающий маршруты между городами; (б): 2 и 3 — последовательности представляющие города, 2–3 — последовательность представляет маршрут между городами; (в): пример соединения городов и маршрутов. Chemistry World
Рисунок 1. Решение задачи коммивояжера. (а): граф, описывающий маршруты между городами; (б): 2 и 3 — последовательности представляющие города, 2–3 — последовательность представляет маршрут между городами; (в): пример соединения городов и маршрутов. Chemistry World 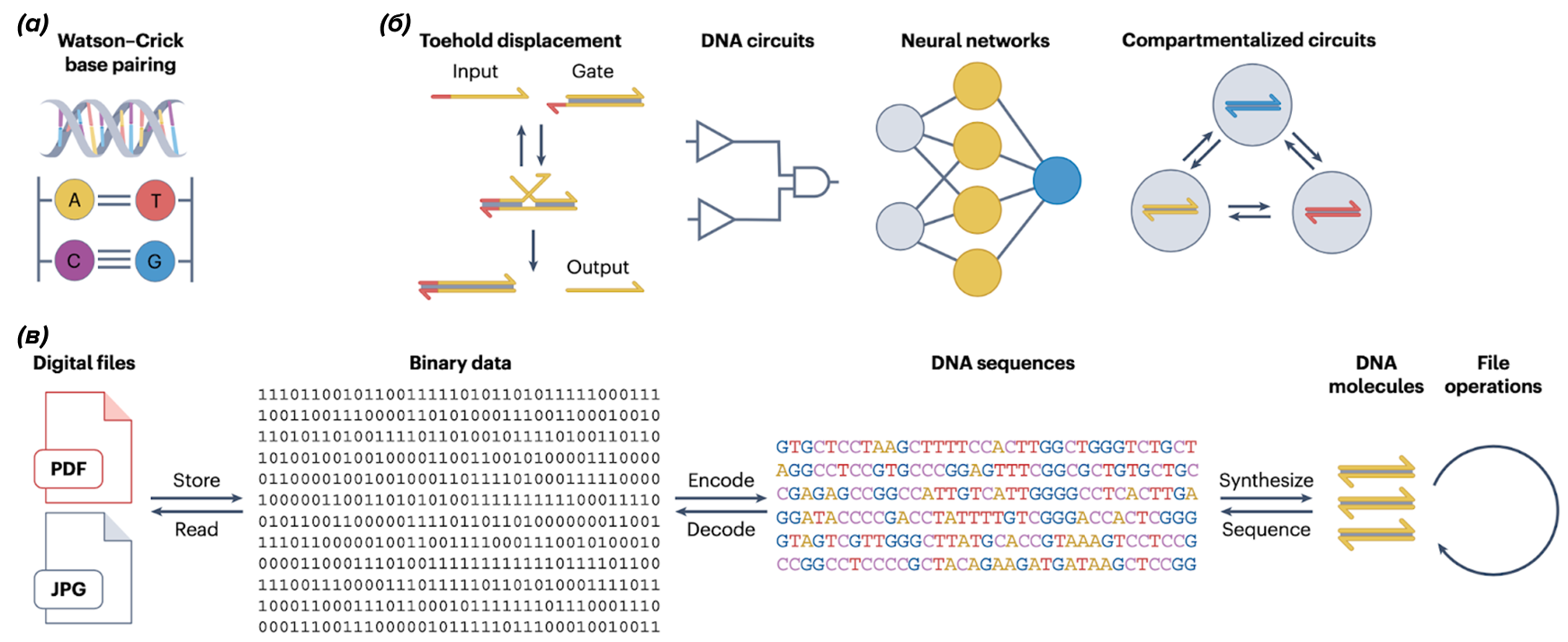 Рисунок 2. Замещение цепочек ДНК. (a) — в ДНК-компьютерах используется способность ДНК связываться комплементарно; (б) — на основе вытеснения одних олигонуклеотидов другими можно создать логические вентили и нейросети. Систему можно усложнить при помощи компартментализации (дополнительных наноструктур в пробирке); (в) — "центральная догма" записи информации в ДНК. [2]
Рисунок 2. Замещение цепочек ДНК. (a) — в ДНК-компьютерах используется способность ДНК связываться комплементарно; (б) — на основе вытеснения одних олигонуклеотидов другими можно создать логические вентили и нейросети. Систему можно усложнить при помощи компартментализации (дополнительных наноструктур в пробирке); (в) — "центральная догма" записи информации в ДНК. [2] 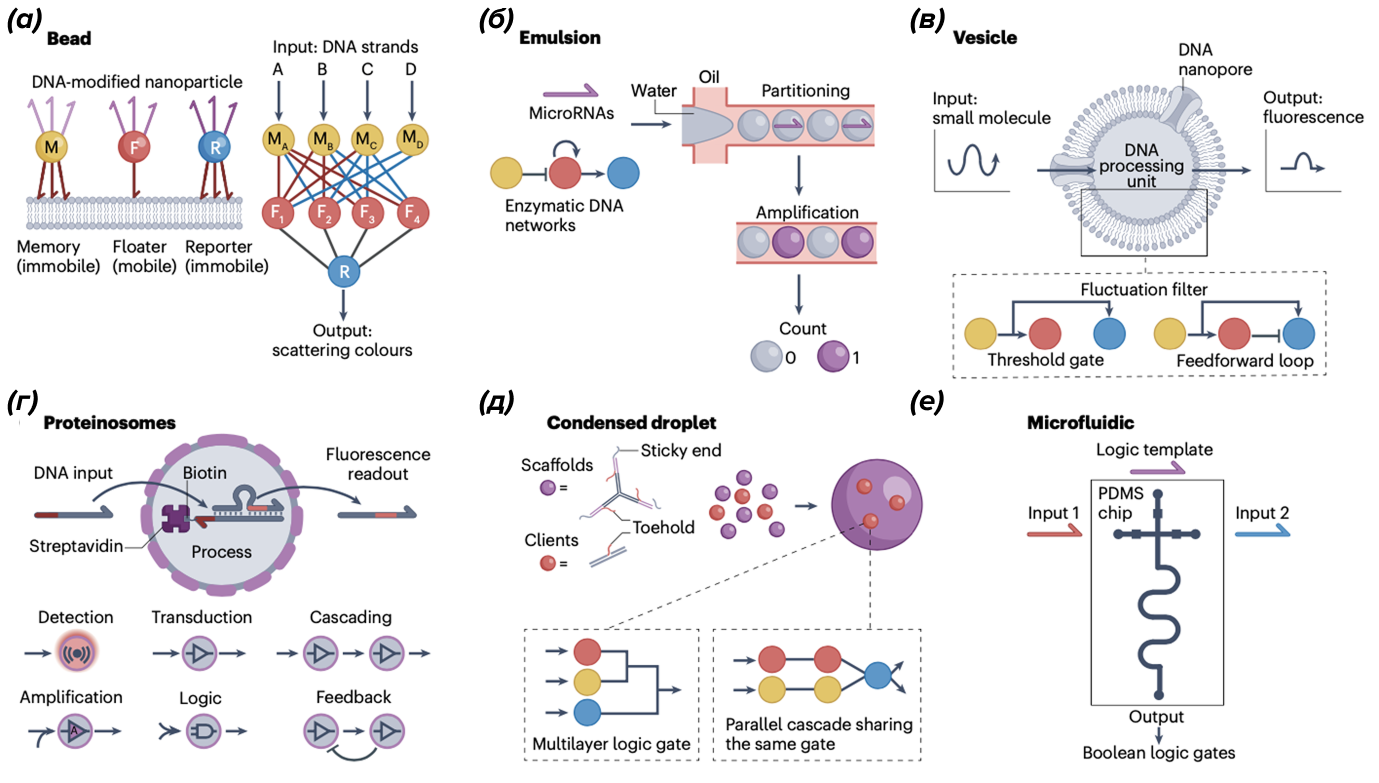 Рисунок 3. ДНК-вычисления на основе наночастиц и компартментализации. (а) — модифицированные ДНК-наночастицы на липидном бислое используются в качестве вычислительной памяти (M), подвижных элементов (F) и репортерных единиц (R). Наночастицы памяти и репортеров неподвижны, тогда как подвижные элементы могут диффундировать и сталкиваться с другими наночастицами. Добавление ДНК-входов изменяет состояния гибридизации в памяти, информация из которых обрабатывается подвижными элементами и затем передается репортеру. Двоичный выход (1 или 0) определяется связыванием или отсутствием связывания между подвижным элементом и репортером, которое различается по цвету рассеяния наночастиц. Комбинация множества наборов памяти, подвижных элементов и репортеров позволяет программировать нейронные сети, подобные перцептрону [2]. (б) — благодаря разделению на капли "вода в масле" ферментативная ДНК-цепь может количественно усиливать и передавать наличие микроРНК; (в) — везикулы, содержащие ДНК-реакционные сети, могут использоваться для восприятия, анализа и обработки непрерывных колебаний внеклеточных стимулов. Ключевым модулем является фильтр колебаний, состоящий из контуров прямой передачи и пороговых элементов; (г) — ДНК-цепи, заключенные в протеиносомы через взаимодействие стрептавидина и биотина, могут воспринимать, обрабатывать и секретировать короткий одноцепочечный выходной ДНК через механизм смещения ДНК-цепи. Отдельные протеиносомы можно настроить для выполнения различных распределенных вычислительных задач, включая обнаружение, преобразование сигналов, каскадирование, усиление, логику и обратную связь; (д) — ДНК-дроплеты могут функционировать как безмембранные компартменты для управления молекулярными вычислениями. Y-образные ДНК-структуры (фиолетовые круги) с самокомплементарными липкими концами (непарные нуклеотиды, которые могут связывать сегменты ДНК) конденсируются в динамические капли, способные вмещать ДНК-клиенты (красные круги) для различных вычислений; (е) — микрофлюидный чип на основе полидиметилсилоксана (PDMS) предоставляет автоматизированное управление и программируемое выполнение логических операций Булевой алгебры. [2]
Рисунок 3. ДНК-вычисления на основе наночастиц и компартментализации. (а) — модифицированные ДНК-наночастицы на липидном бислое используются в качестве вычислительной памяти (M), подвижных элементов (F) и репортерных единиц (R). Наночастицы памяти и репортеров неподвижны, тогда как подвижные элементы могут диффундировать и сталкиваться с другими наночастицами. Добавление ДНК-входов изменяет состояния гибридизации в памяти, информация из которых обрабатывается подвижными элементами и затем передается репортеру. Двоичный выход (1 или 0) определяется связыванием или отсутствием связывания между подвижным элементом и репортером, которое различается по цвету рассеяния наночастиц. Комбинация множества наборов памяти, подвижных элементов и репортеров позволяет программировать нейронные сети, подобные перцептрону [2]. (б) — благодаря разделению на капли "вода в масле" ферментативная ДНК-цепь может количественно усиливать и передавать наличие микроРНК; (в) — везикулы, содержащие ДНК-реакционные сети, могут использоваться для восприятия, анализа и обработки непрерывных колебаний внеклеточных стимулов. Ключевым модулем является фильтр колебаний, состоящий из контуров прямой передачи и пороговых элементов; (г) — ДНК-цепи, заключенные в протеиносомы через взаимодействие стрептавидина и биотина, могут воспринимать, обрабатывать и секретировать короткий одноцепочечный выходной ДНК через механизм смещения ДНК-цепи. Отдельные протеиносомы можно настроить для выполнения различных распределенных вычислительных задач, включая обнаружение, преобразование сигналов, каскадирование, усиление, логику и обратную связь; (д) — ДНК-дроплеты могут функционировать как безмембранные компартменты для управления молекулярными вычислениями. Y-образные ДНК-структуры (фиолетовые круги) с самокомплементарными липкими концами (непарные нуклеотиды, которые могут связывать сегменты ДНК) конденсируются в динамические капли, способные вмещать ДНК-клиенты (красные круги) для различных вычислений; (е) — микрофлюидный чип на основе полидиметилсилоксана (PDMS) предоставляет автоматизированное управление и программируемое выполнение логических операций Булевой алгебры. [2] 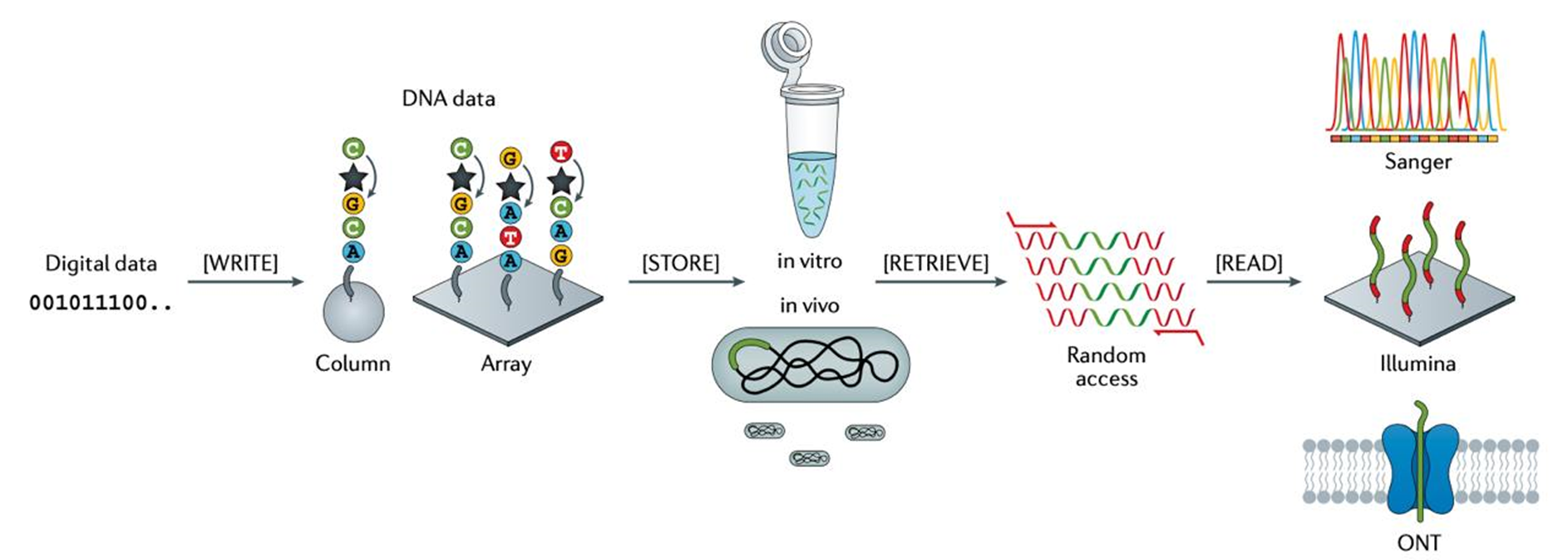 Рисунок 4. Система хранения данных на базе ДНК. [3]
Рисунок 4. Система хранения данных на базе ДНК. [3] 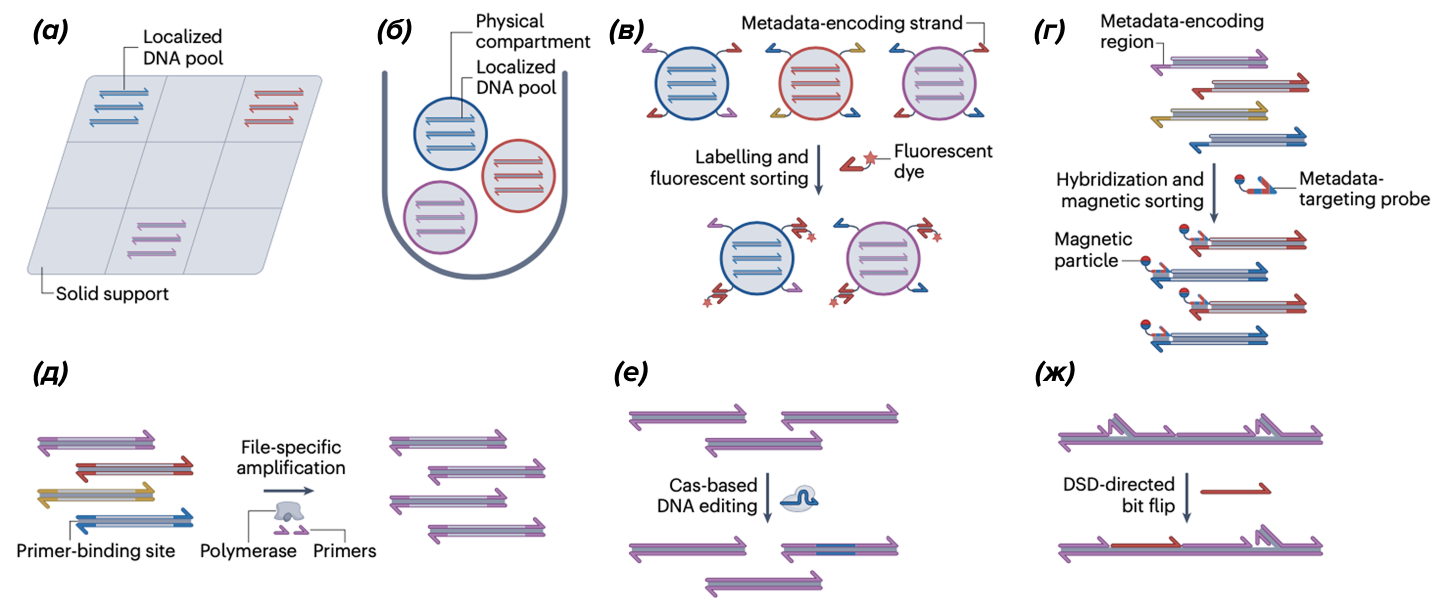 Рисунок 5. (а), (б) — положенные на хранение ДНК физически отделяют друг от друга, помещая в разные ячейки, чтобы они не перепутались. В (а) молекулы ДНК хранятся вне воды, в разных ячейках специальной структуры. В (б) молекулы ДНК помещаются в разные структуры внутри раствора. (в) — на структуры-хранилища ДНК вешаются флуоресцентные метки для облегчения сортировки. (г) — на ДНК вешаются магнитные частицы. (д), (е) — после того, как ДНК-хранилище данных было синтезировано, его можно редактировать при помощи CRISPR—Cas. (ж) — редактирование сохраненных данных при помощи замещения цепи ( strand displacement, DSD). [3]
Рисунок 5. (а), (б) — положенные на хранение ДНК физически отделяют друг от друга, помещая в разные ячейки, чтобы они не перепутались. В (а) молекулы ДНК хранятся вне воды, в разных ячейках специальной структуры. В (б) молекулы ДНК помещаются в разные структуры внутри раствора. (в) — на структуры-хранилища ДНК вешаются флуоресцентные метки для облегчения сортировки. (г) — на ДНК вешаются магнитные частицы. (д), (е) — после того, как ДНК-хранилище данных было синтезировано, его можно редактировать при помощи CRISPR—Cas. (ж) — редактирование сохраненных данных при помощи замещения цепи ( strand displacement, DSD). [3]